
Deep-Tech Decoded: #11 Robot Training 101, Part 3: How Robots Learn What Happens Next with World Models

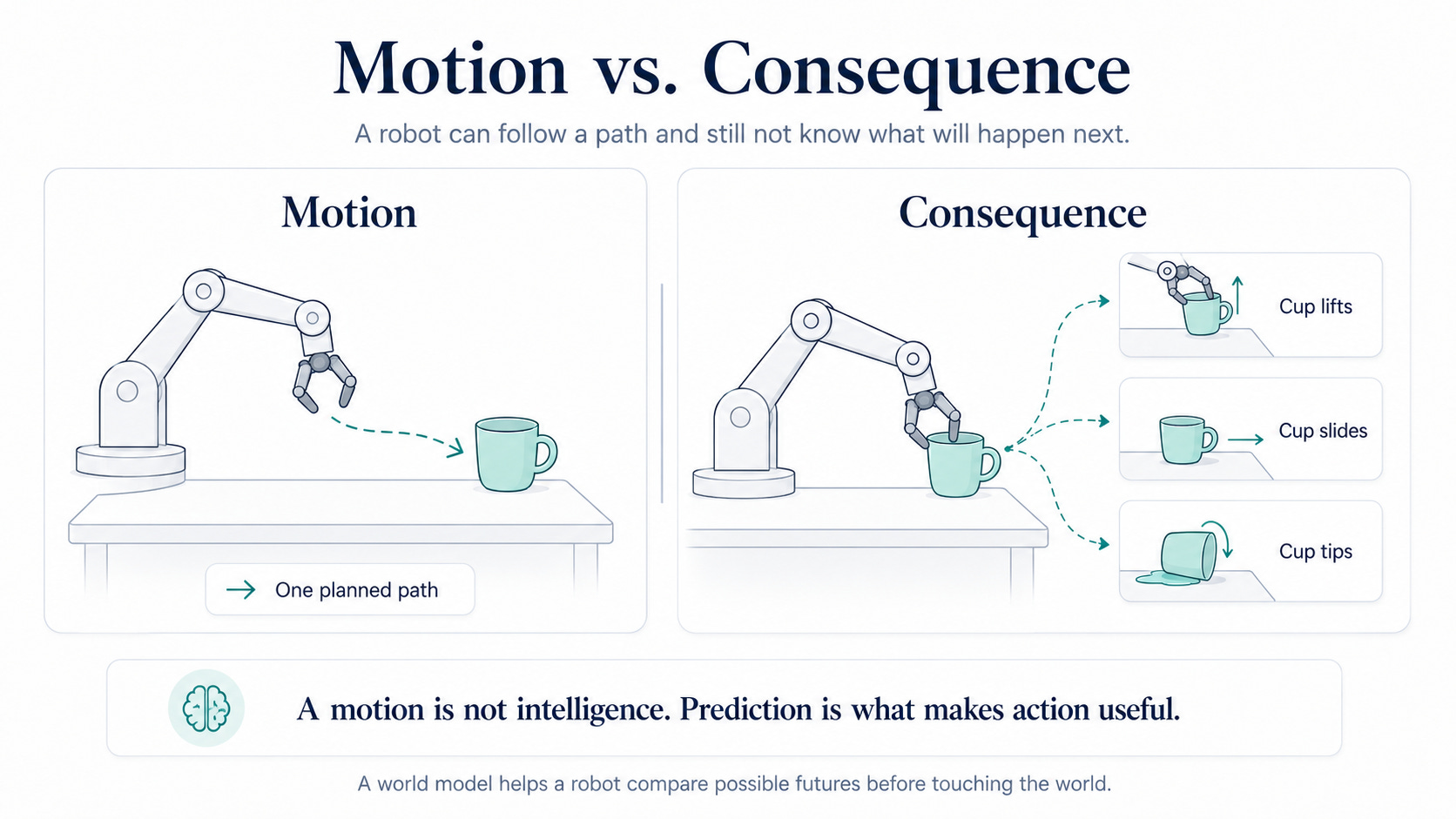
A robot can move its gripper toward a cup and still not understand the cup.
The motion may be correct. But the consequence is still unknown.
The cup might lift cleanly. It might slide away. It might tip over. It might spill. It might be heavier than it looks. It might be stuck to a coaster. The robot may touch the cup, but the important question comes after contact:
What happens next?
That is the gap between motion and intelligence.
A robot does not just need to know what to do. It needs to know what its action will do to the world.
That is where world models come in.
The difference between a robot that follows a motion and a robot that behaves intelligently is prediction. A world model is the layer that lets a robot ask:
What happens next if I do this?
From policy and data to prediction
In Part 1, we talked about policies: how robots choose actions. A policy maps what the robot observes to what it should do next. If the robot sees a cup, the policy may tell it to move the gripper toward the handle.
In Part 2, we talked about data: what robots need to learn from. Robot data is not just video. It is interaction data: what the robot saw, what it did, what it felt, and what happened next.
Now we move to the next layer: prediction. If the policy says, “move this way,” the world model asks, “what will happen if I move this way?”
A policy chooses. A world model predicts.
A short history: from mental models to game dreams to physical prediction
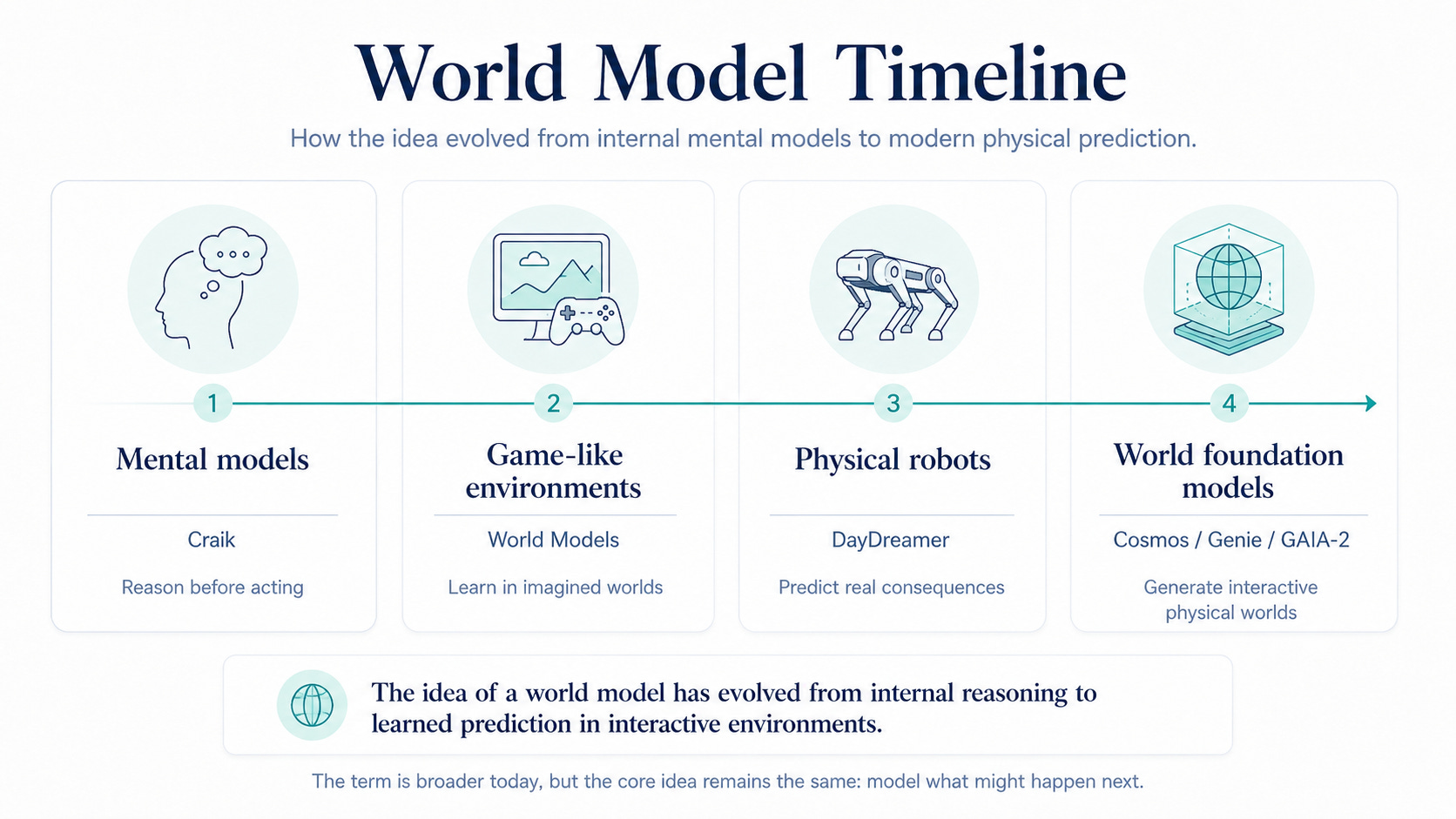
World models are not a brand-new idea.
The deeper root is the old idea that intelligent systems use internal models of reality to reason before acting. Kenneth Craik is often credited with formalizing this idea in 1943: the mind can construct “small-scale models” of reality to anticipate events before they occur.
The modern AI version became famous through David Ha and Jürgen Schmidhuber’s 2018 paper World Models. Their agent learned a compressed representation of game-like environments such as CarRacing and VizDoom, then used that learned model for control.
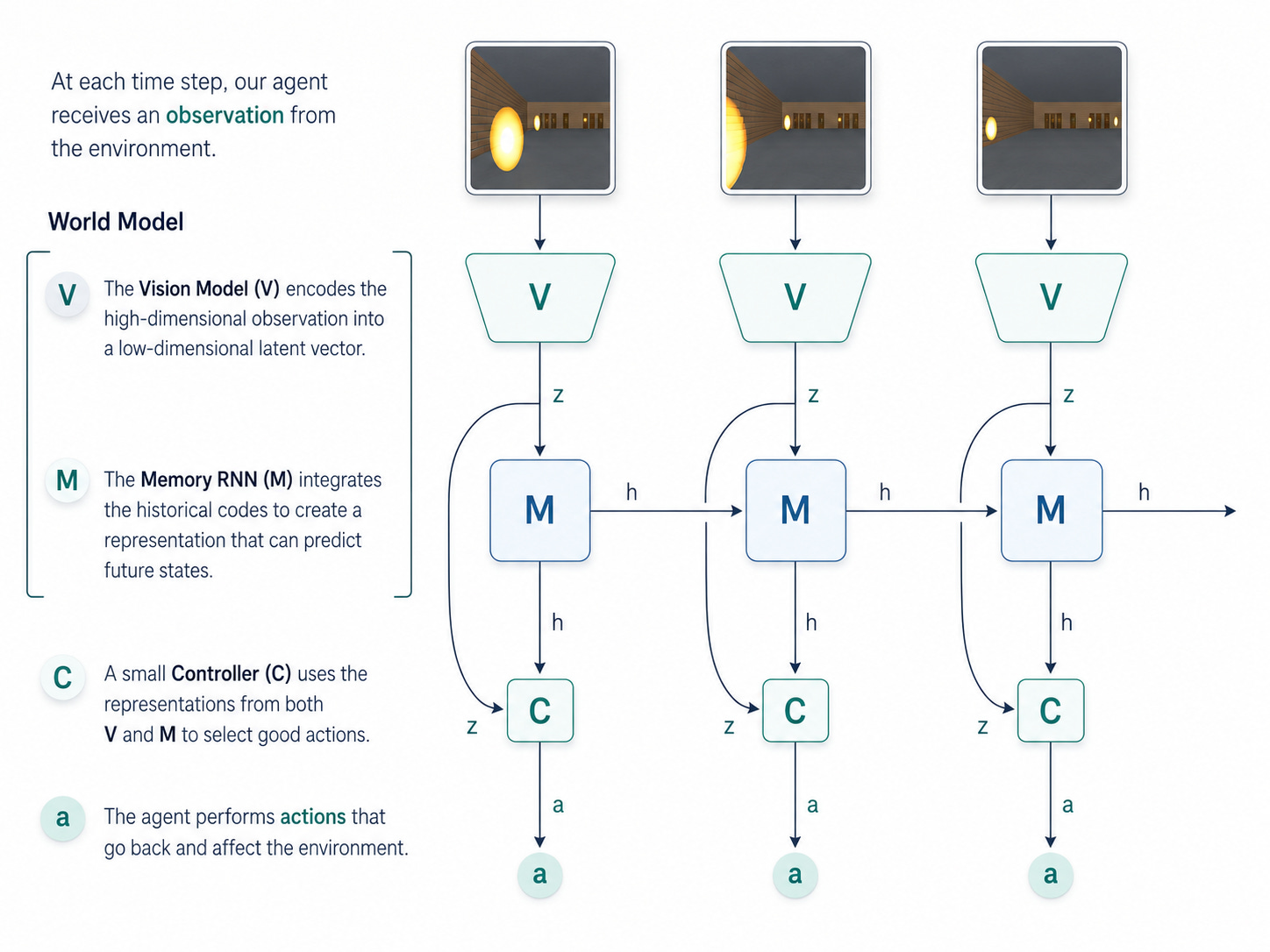
That game setting matters. Games are controlled worlds. The rules are hidden, but stable. If an agent can learn the dynamics of the game, it can plan inside its learned version of that world.
Robotics makes the idea harder and more useful. A physical robot cannot cheaply crash, drop, fall, or break things millions of times. DayDreamer applied Dreamer-style world models directly to real robots, including a quadruped, robot arms, and a wheeled robot, to learn from physical interaction with less dependence on simulators.
Today, the term is also used more broadly. NVIDIA describes Cosmos as a world foundation model platform for physical AI and robotics workflows. Google DeepMind describes Genie 3 as a general-purpose world model for generating interactive environments. Wayve describes GAIA-2 as a controllable video-generative world model for autonomous driving.
So the arc is not just “games to robots.” It is:
mental models → game dreams → physical prediction → generated worlds
What is a world model?
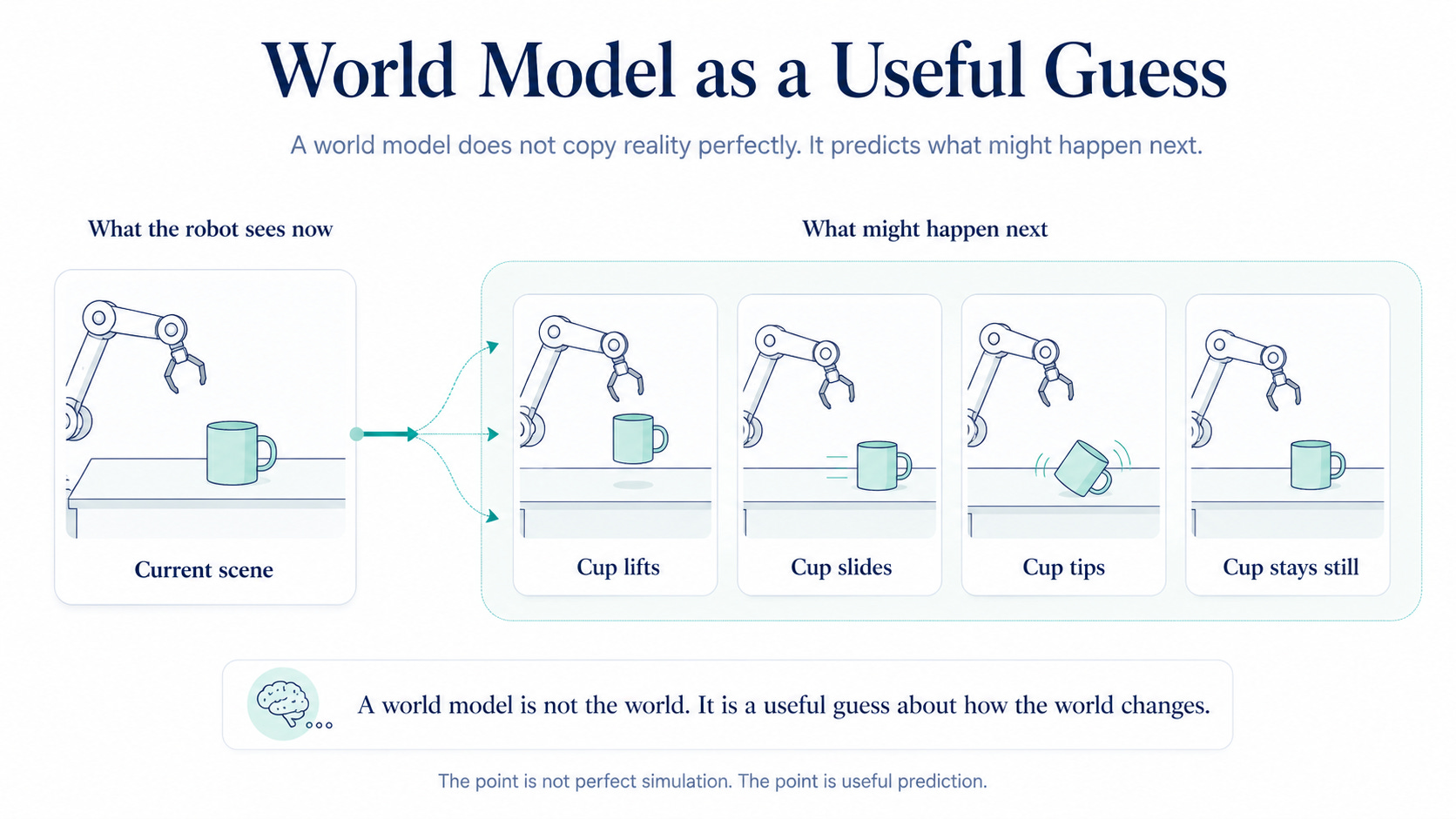
A world model is the robot’s internal predictor of what might happen next.
It does not need to perfectly simulate the universe. It does not need to model every molecule, reflection, or microscopic contact point.
It only needs to be useful.
If the robot pushes a cup, the world model predicts whether the cup may slide, tip, or stay still.
If the robot reaches around a chair, it predicts whether the arm may collide.
If the robot places a plate near the table edge, it predicts whether the placement is stable.
A world model is not the world. It is a useful guess about how the world changes.
This is why world models are so appealing in robotics. They give the robot a way to rehearse possible futures before acting in the physical world.
Policy vs. world model
The easiest way to understand a world model is to contrast it with a policy.
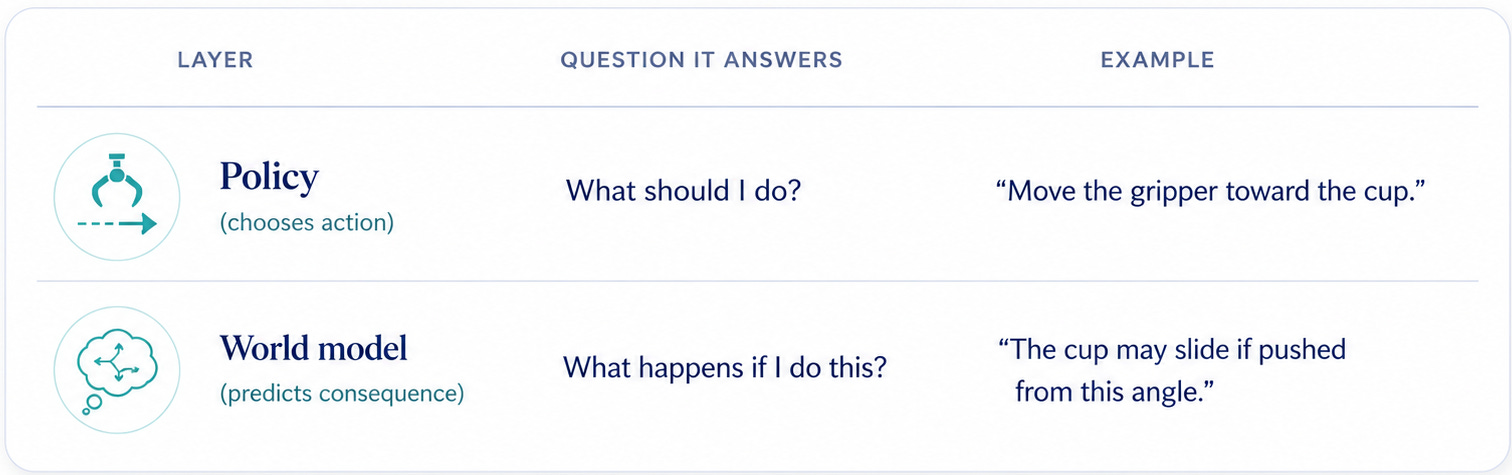
A policy might output: pull the drawer.
A world model predicts: the drawer may open, jam, resist, or collide with the object in front of it.
A policy is the action chooser. A world model is the consequence predictor.
The best systems may use both. The policy proposes actions. The world model helps evaluate what those actions might cause. Then the robot can choose a safer, more useful, or more reliable action.
This is robot imagination - not imagination in the poetic sense, but in the practical sense of testing futures before touching the world.
Why prediction is harder in robotics
Prediction is hard in every domain. In robotics, it is physically hard.
The world pushes back.
A cup behaves differently depending on its weight, surface friction, grip angle, and whether it is full.
A towel can fold, bunch, stretch, wrinkle, or slip.
A cable can bend, tangle, snag, or resist being pulled.
A humanoid footstep can stabilize the body or make it fall.
A person can unexpectedly move into the robot’s path.
This is different from predicting the next word in a sentence. The robot’s action changes the world, and the changed world becomes the next problem.
Small errors compound. A slightly bad grasp changes the object pose. The changed object pose makes the next action harder. The next action creates a new state the robot may not have seen before.
Physical intelligence is consequence-aware intelligence.
The robot does not just need to identify a cup. It needs to predict the future of the cup under action.

A practical map of world models
I don’t think there is one universally accepted taxonomy of world models. Researchers and companies categorize them by architecture, modality, training objective, or use case.
But as an ex consultant I always have the urge to structure things, so I tried to make a practical taxonomy here - not a canonical industry standard, but a reader-friendly map to separate ideas that often get collapsed into the same phrase.
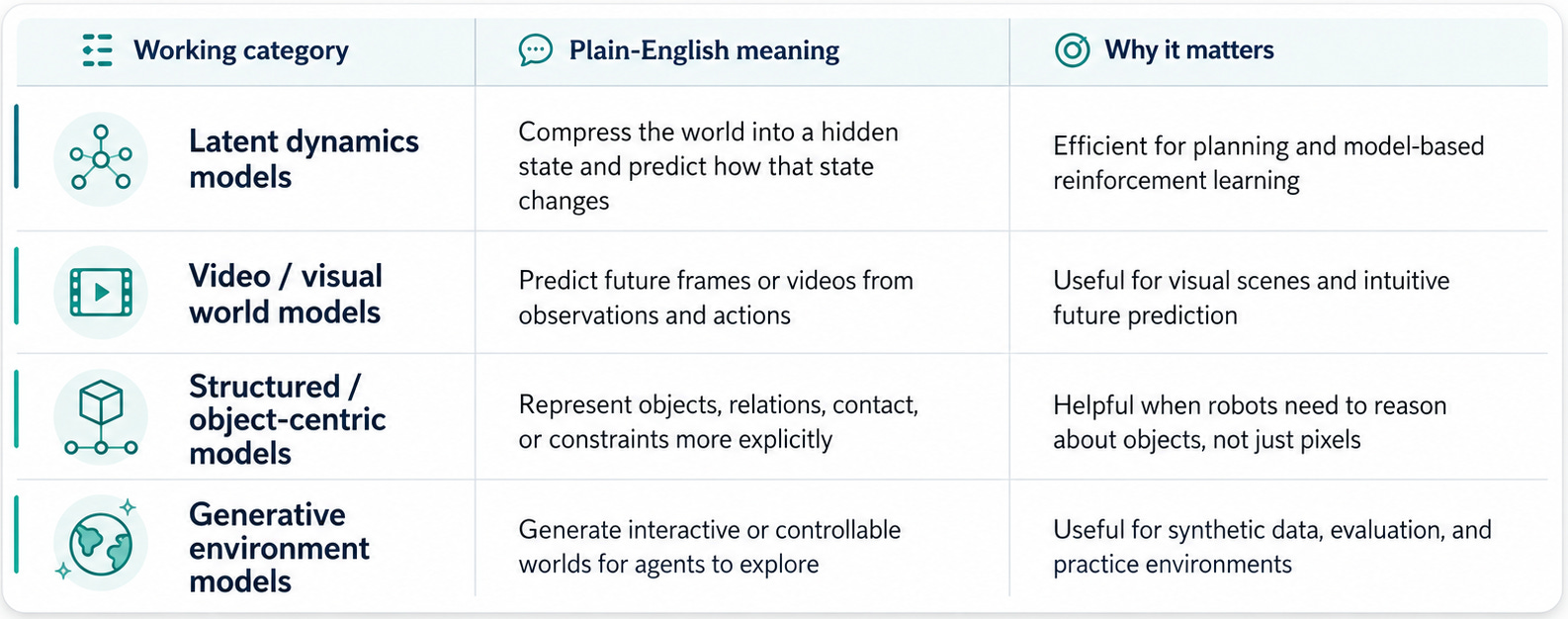
The important point is not the taxonomy itself.
The important point is that “world model” is less a single architecture than a job description:
Predict how the world changes.
Some world models predict in a compact hidden space. Some predict videos. Some represent objects more explicitly. Some generate environments.
They are different ways of answering the same question: what might happen next?
What must a robot world model learn?
A robot world model needs to learn more than appearance.
It needs to learn the ingredients of physical consequence.
Objects: What things are, where they are, and how they can move
Physics: Sliding, falling, rolling, balance, resistance
Contact: What happens when the robot touches, pushes, grasps, or pulls
Time: How small actions compound into future states
Agents: How humans, pets, or other robots may move nearby
Uncertainty: When the robot should be unsure and act cautiously
Contact is especially hard.
Before contact, vision can do a lot. The robot can see the cup, estimate its position, and plan a path.
After contact, the world becomes less predictable. The cup may slip. The gripper may press too hard. The surface may be sticky. The object may deform. A tiny difference in angle can change the outcome.
The world is not just a scene. It is a set of possible futures.
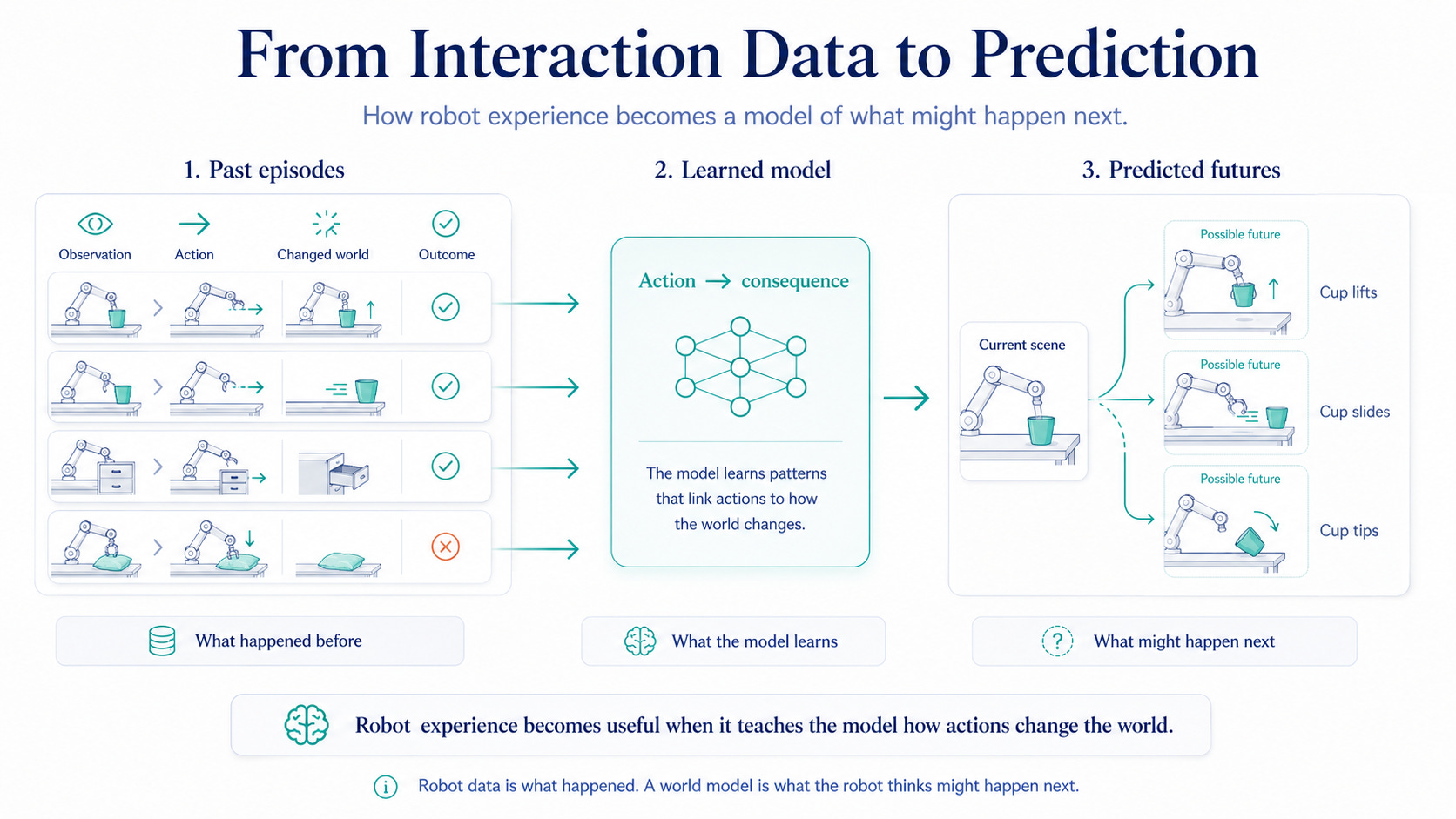
From experience to prediction
This is where world models connect back to robot data.
Article 2 was about the ingredients: the data stack. What signal was captured? Which body produced it? What task was attempted? How was the data collected? How much time did it cover?
A world model uses that data differently.
It does not just store what happened. It learns patterns between action and consequence.
A static image can teach what a drawer looks like.
A robot episode can teach: reach toward handle, touch handle, pull, drawer opens.
A failure trace can teach: pull from the wrong angle, drawer jams.
A deployment log can teach: the same action sometimes succeeds and sometimes fails depending on object weight, friction, prior state, lighting, or human interruption.
Robot data is what happened. A world model is what the robot thinks might happen next.
A few robot-relevant world models worth knowing
The robotics industry is not using one single “world model.” The field is still early, and different teams use the phrase in different ways.
A more useful way to read the market is to look at where world models are showing up in robot learning workflows. I’ll call out some world models that I feel like are being actively used / discussed.
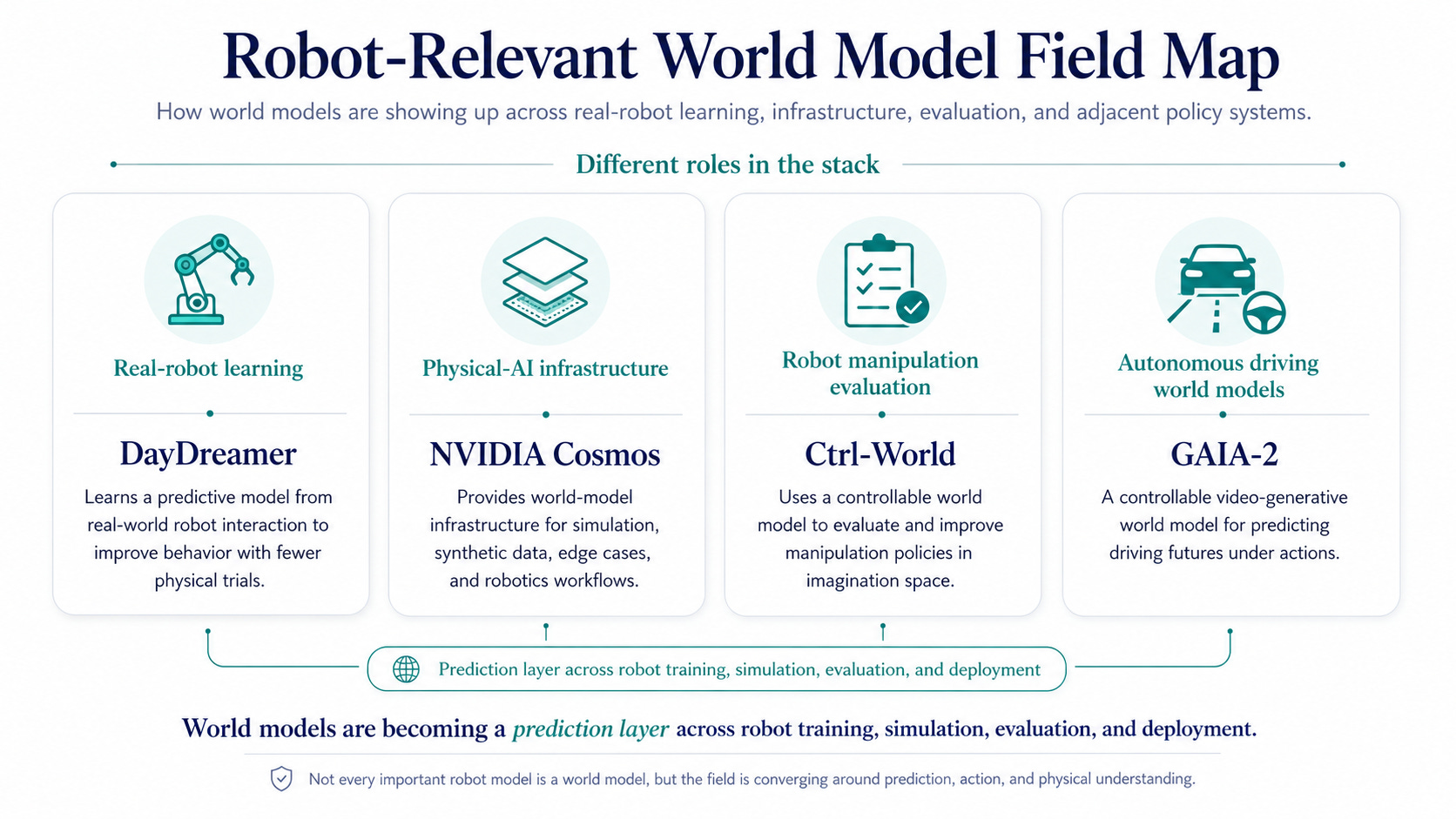
DayDreamer is one of the cleanest robotics examples. It applied Dreamer-style world models directly to physical robots, including robot arms, a quadruped, and a wheeled robot. The important idea is not that every robot company uses DayDreamer specifically. It is that a robot can learn a predictive model from real-world interaction, then use that model to improve behavior with fewer physical trials.
NVIDIA Cosmos represents the “world foundation model” direction for physical AI. NVIDIA positions Cosmos as a platform for building customized world models for robotics and autonomous vehicles, including predictive video worlds, synthetic data, edge cases, and robot-centric simulation. This is less about one robot policy and more about infrastructure: giving robotics teams a way to generate, simulate, and reason about physical scenarios before deploying in the real world.

Ctrl-World is a newer research example (2026) that gets closer to the problem robot companies actually care about: evaluating and improving generalist robot policies without running endless real-world rollouts. It is a controllable, multi-view world model for robot manipulation, trained on DROID trajectories, and designed to let policies roll out in “imagination space.” The paper reports that it can rank policy performance without real-world rollouts and improve policy success through synthetic successful trajectories.
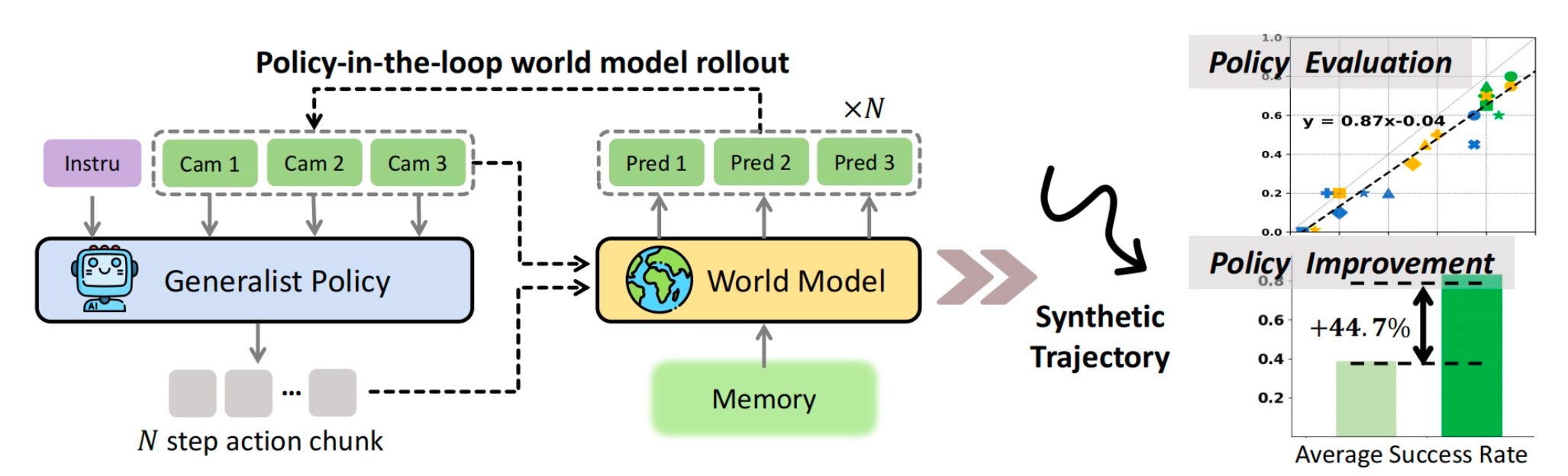
Wayve GAIA-2 is not a household-robot model, but it is useful as an autonomous-driving example of where world models are commercially heading. Wayve describes GAIA-2 as a controllable video-generative world model for driving, using video, text, and action inputs to generate possible driving futures. Driving is a more constrained robotics domain than general-purpose manipulation, but the underlying logic is similar: predict how the world may evolve under actions.
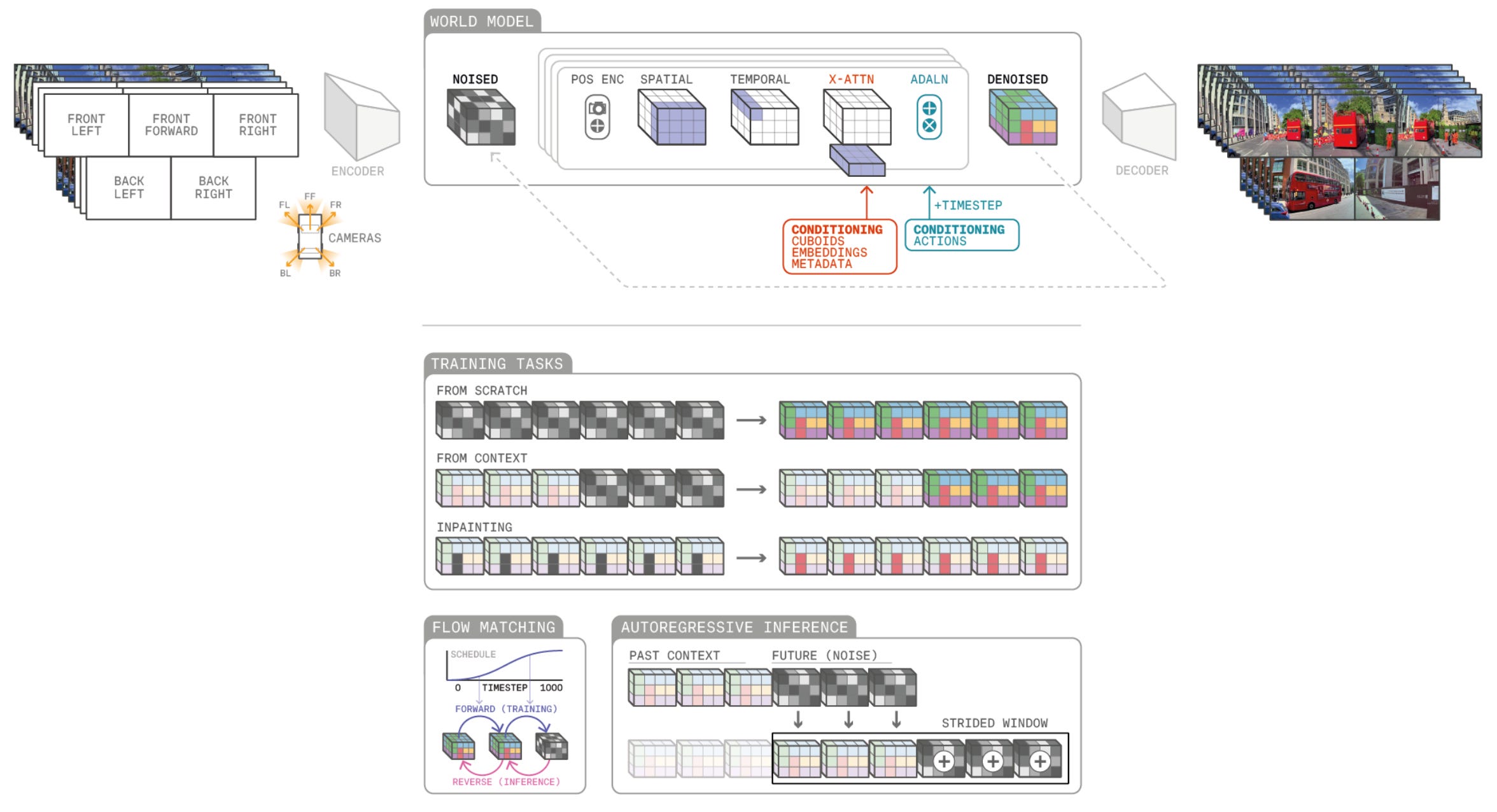
The takeaway is simple: in robotics, “world model” is becoming less of a single model category and more of a prediction layer across the training stack.
Some world models help robots practice in imagination.
Some help generate synthetic scenarios.
Some help evaluate policies before physical rollout.
Some are merging into broader robot foundation models.
Not every important robot model is a world model. But many frontier systems are circling the same problem:
How do we connect physical understanding, prediction, and action?
Why world models could change the robotics race
World models matter because real-world trial and error is expensive.
A robot that can predict consequences can test more options before acting.
It can imagine several grasps before touching the object.
It can predict whether a package will slide before pushing it.
It can estimate whether a humanoid step is stable before shifting weight.
It can notice that opening a cabinet might collide with something nearby.
This can improve planning, safety, recovery, sample efficiency, and generalization.
But world models are not magic.
A bad world model can be worse than no world model if the robot trusts it too much. If the model predicts that a glass will stay stable but the glass tips, the robot still fails. If the model underestimates human movement, safety can break. If the model was trained on clean lab data, it may not predict messy homes or factories.
The goal is not to simulate the whole universe.
The goal is to predict enough of the next few seconds to act better.
For robotics companies, that could become a major advantage. The best systems will not only collect embodied data. They will turn that data into better predictions, better evaluations, safer actions, and faster learning loops.
Better prediction can turn the same experience into better behavior.
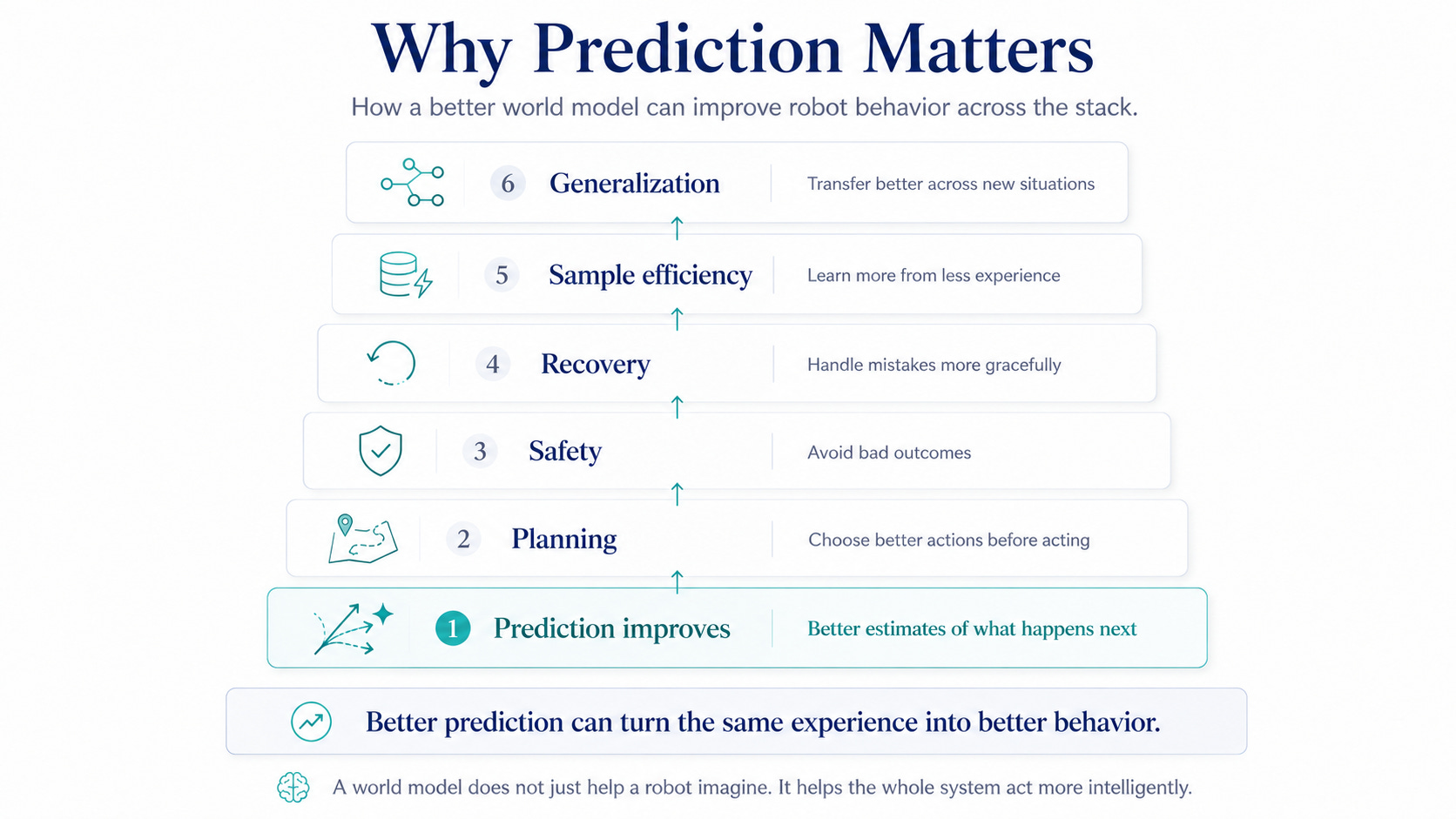
Consequence-aware robots
A robot does not need perfect physics for every object in a kitchen.
It needs enough prediction to avoid breaking the glass, spilling the drink, crushing the fruit, tangling the cable, or trapping itself in a bad state.
That is why world models matter.
They are not just another technical module. They are a way to make robot intelligence less reactive and more consequence-aware.
A policy tells the robot what to do.
A world model helps it understand what the world might do back.
The robot that wins may not be the one that moves fastest.
It may be the one that best understands what its movement will cause.